# Node.js
# Nodejs vs Browser
各个浏览器厂商会开发解析 Javascript 的引擎如 google chrome、Apple safari。因为不同厂商的引擎对 ecmascript 的解析程序不同,所以有些功能可能在有的浏览器有效,但在其他的浏览器无效。
比较著名的引擎是 chrome 的 v8,它是由 c++编写的,而且它有个特点可以内置到其他 C++程序中,这就为 node.js 的实现提供的基础。所以可以把 nodejs 简单来理解为使用 v8 引擎可以解析 javascript 语法,同时也可以调用 c++功能进行文件操作,网络通信等功能。
- nodejs 是开源、跨平台的 javascript 运行时环境,它是运行时,不是语言或框架,是在浏览器之外的 Javascript 使用
- nodejs 可以使用 javascript 调用 c++,实现计算底层操作
- nodejs 运行时包含 v8 引擎(解析 javascript)、libuv (进行计算机文件、网络等底层操作) 等等。通过查看 nodejs 源码,我们会知道 nodejs 使用 c++进行文件或网络操作
- nodejs 使用 libuv 库,让开发者使用 javascript 调用 c++程序
- nodejs 没有基于浏览器的 javascript 的 DOM、BOM 等概念这与但是拥有文件系统操作功能
- nodejs 我们可以随意选择版本,但浏览器的 javascript 运行在众多用户电脑中,所以版本不是由我们决定的
# 对 Node.js 的理解?优缺点?应用场景?
# 一、是什么
Node.js 是一个开源与跨平台的 JavaScript 运行时环境
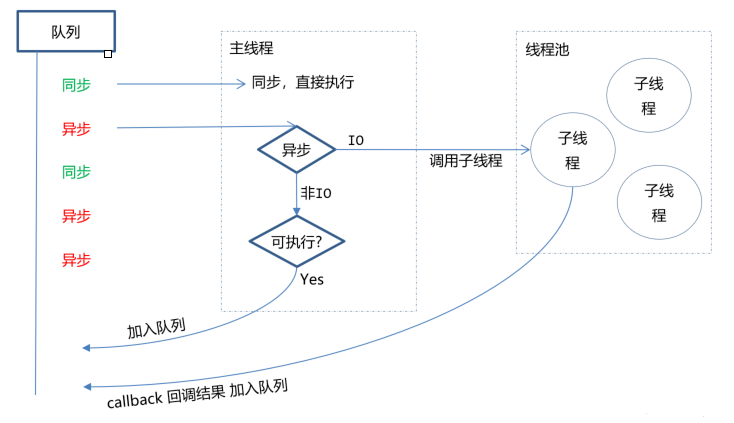
在浏览器外运行 V8 JavaScript 引擎(Google Chrome 的内核),利用事件驱动、非阻塞和异步输入输出模型等技术提高性能
可以理解为 Node.js 就是一个服务器端的、非阻塞式 I/O 的、事件驱动的JavaScript运行环境
# 非阻塞异步
Nodejs采用了非阻塞型I/O机制,在做I/O操作的时候不会造成任何的阻塞,当完成之后,以时间的形式通知执行操作
例如在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率
# 事件驱动
事件驱动就是当进来一个新的请求的时,请求将会被压入一个事件队列中,然后通过一个循环来检测队列中的事件状态变化,如果检测到有状态变化的事件,那么就执行该事件对应的处理代码,一般都是回调函数
比如读取一个文件,文件读取完毕后,就会触发对应的状态,然后通过对应的回调函数来进行处理
# 二、优缺点
优点:
- 处理高并发场景性能更佳
- 适合 I/O 密集型应用,值的是应用在运行极限时,CPU 占用率仍然比较低,大部分时间是在做 I/O 硬盘内存读写操作
因为Nodejs是单线程,带来的缺点有:
- 不适合 CPU 密集型应用
- 只支持单核 CPU,不能充分利用 CPU
- 可靠性低,一旦代码某个环节崩溃,整个系统都崩溃
# 三、应用场景
借助Nodejs的特点和弊端,其应用场景分类如下:
- 善于
I/O,不善于计算。因为 Nodejs 是一个单线程,如果计算(同步)太多,则会阻塞这个线程 - 大量并发的 I/O,应用程序内部并不需要进行非常复杂的处理
- 与 websocket 配合,开发长连接的实时交互应用程序
具体场景可以表现为如下:
- 第一大类:用户表单收集系统、后台管理系统、实时交互系统、考试系统、联网软件、高并发量的 web 应用程序 (后端开发,Nodejs 的异步 I/O 天生适合做 Web 高并发)
- 第二大类:基于 web、canvas 等多人联网游戏
- 第三大类:基于 web 的多人实时聊天客户端、聊天室、图文直播
- 第四大类:单页面浏览器应用程序, (前端基建,Webpack、Gulp、Babel、Jest 等等前端工程化的工具或插件。)
- 第五大类:操作数据库、为前端和移动端提供基于
json的 API (BFF 开发,比如 SSR 中间层或者 GraphQL 中间层。)
其实,Nodejs能实现几乎一切的应用,只考虑适不适合使用它
# 参考文献
- http://nodejs.cn/
- https://segmentfault.com/a/1190000019854308
- https://segmentfault.com/a/1190000005173218
# Node. js 有哪些全局对象?
# 一、是什么
在浏览器 JavaScript 中,通常window 是全局对象, 而 Nodejs中的全局对象是 global
在NodeJS里,是不可能在最外层定义一个变量,因为所有的用户代码都是当前模块的,只在当前模块里可用,但可以通过exports对象的使用将其传递给模块外部
所以,在NodeJS中,用var声明的变量并不属于全局的变量,只在当前模块生效
像上述的global全局对象则在全局作用域中,任何全局变量、函数、对象都是该对象的一个属性值
# 二、有哪些
将全局对象分成两类:
- 真正的全局对象
- 模块级别的全局变量
# 真正的全局对象
下面给出一些常见的全局对象:
- Class:Buffer
- process
- console
- clearInterval、setInterval
- clearTimeout、setTimeout
- global
# Class:Buffer
可以处理二进制以及非Unicode编码的数据
在Buffer类实例化中存储了原始数据。Buffer类似于一个整数数组,在 V8 堆原始存储空间给它分配了内存
一旦创建了Buffer实例,则无法改变大小
# process
进程对象,提供有关当前进程的信息和控制
包括在执行node程序进程时,如果需要传递参数,我们想要获取这个参数需要在process内置对象中
启动进程:
node index.js 参数1 参数2 参数3
index.js 文件如下:
process.argv.forEach((val, index) => {
console.log(`${index}: ${val}`)
})
输出如下:
;/usr/acllo / bin / node / Users / mjr / work / node / process - args.js
参数1
参数2
参数3
除此之外,还包括一些其他信息如版本、操作系统等

# console
用来打印stdout和stderr
最常用的输入内容的方式:console.log
console.log('hello')
清空控制台:console.clear
console.clear
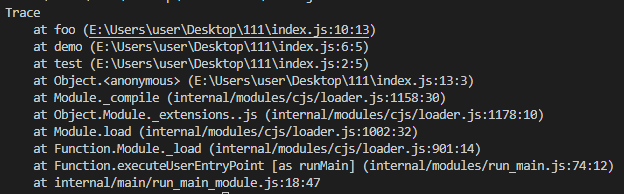
打印函数的调用栈:console.trace
function test() {
demo()
}
function demo() {
foo()
}
function foo() {
console.trace()
}
test()
# clearInterval、setInterval
设置定时器与清除定时器
setInterval(callback, delay[, ...args])
callback每delay毫秒重复执行一次
clearInterval则为对应发取消定时器的方法
# clearTimeout、setTimeout
设置延时器与清除延时器
setTimeout(callback,delay[,...args])
callback在delay毫秒后执行一次
clearTimeout则为对应取消延时器的方法
# global
全局命名空间对象,墙面讲到的process、console、setTimeout等都有放到global中
console.log(process === global.process) // true
# 模块级别的全局对象
这些全局对象是模块中的变量,只是每个模块都有,看起来就像全局变量,像在命令交互中是不可以使用,包括:
- __dirname
- __filename
- exports
- module
- require
# __dirname
获取当前文件所在的路径,不包括后面的文件名
从 /Users/mjr 运行 node example.js:
console.log(__dirname)
// 打印: /Users/mjr
# __filename
获取当前文件所在的路径和文件名称,包括后面的文件名称
从 /Users/mjr 运行 node example.js:
console.log(__filename)
// 打印: /Users/mjr/example.js
# exports
module.exports 用于指定一个模块所导出的内容,即可以通过 require() 访问的内容
exports.name = name
exports.age = age
exports.sayHello = sayHello
# module
对当前模块的引用,通过module.exports 用于指定一个模块所导出的内容,即可以通过 require() 访问的内容
# require
用于引入模块、 JSON、或本地文件。 可以从 node_modules 引入模块。
可以使用相对路径引入本地模块或JSON文件,路径会根据__dirname定义的目录名或当前工作目录进行处理
# 参考文献
- http://nodejs.cn/api/globals.html
# 对 Node 中的 process 的理解?有哪些常用方法?
# 一、是什么
process 对象是一个全局变量,提供了有关当前 Node.js进程的信息并对其进行控制,作为一个全局变量
我们都知道,进程计算机系统进行资源分配和调度的基本单位,是操作系统结构的基础,是线程的容器
当我们启动一个js文件,实际就是开启了一个服务进程,每个进程都拥有自己的独立空间地址、数据栈,像另一个进程无法访问当前进程的变量、数据结构,只有数据通信后,进程之间才可以数据共享
由于JavaScript是一个单线程语言,所以通过node xxx启动一个文件后,只有一条主线程
# 二、属性与方法
关于process常见的属性有如下:
- process.env:环境变量,例如通过 `process.env.NODE_ENV 获取不同环境项目配置信息
- process.nextTick:这个在谈及
EventLoop时经常为会提到 - process.pid:获取当前进程 id
- process.ppid:当前进程对应的父进程
- process.cwd():获取当前进程工作目录,
- process.platform:获取当前进程运行的操作系统平台
- process.uptime():当前进程已运行时间,例如:pm2 守护进程的 uptime 值
- 进程事件: process.on(‘uncaughtException’,cb) 捕获异常信息、 process.on(‘exit’,cb)进程推出监听
- 三个标准流: process.stdout 标准输出、 process.stdin 标准输入、 process.stderr 标准错误输出
- process.title 指定进程名称,有的时候需要给进程指定一个名称
下面再稍微介绍下某些方法的使用:
process.cwd()
返回当前 Node进程执行的目录
一个Node 模块 A 通过 NPM 发布,项目 B 中使用了模块 A。在 A 中需要操作 B 项目下的文件时,就可以用 process.cwd() 来获取 B 项目的路径
process.argv
在终端通过 Node 执行命令的时候,通过 process.argv 可以获取传入的命令行参数,返回值是一个数组:
- 0: Node 路径(一般用不到,直接忽略)
- 1: 被执行的 JS 文件路径(一般用不到,直接忽略)
- 2~n: 真实传入命令的参数
所以,我们只要从 process.argv[2] 开始获取就好了
const args = process.argv.slice(2)
process.env
返回一个对象,存储当前环境相关的所有信息,一般很少直接用到。
一般我们会在 process.env 上挂载一些变量标识当前的环境。比如最常见的用 process.env.NODE_ENV 区分 development 和 production
在 vue-cli 的源码中也经常会看到 process.env.VUE_CLI_DEBUG 标识当前是不是 DEBUG 模式
process.nextTick()
我们知道NodeJs是基于事件轮询,在这个过程中,同一时间只会处理一件事情
在这种处理模式下,process.nextTick()就是定义出一个动作,并且让这个动作在下一个事件轮询的时间点上执行
例如下面例子将一个foo函数在下一个时间点调用
function foo() {
console.error('foo')
}
process.nextTick(foo)
console.error('bar')
输出结果为bar、foo
虽然下述方式也能实现同样效果:
setTimeout(foo, 0)
console.log('bar')
两者区别在于:
- process.nextTick()会在这一次 event loop 的 call stack 清空后(下一次 event loop 开始前)再调用 callback
- setTimeout()是并不知道什么时候 call stack 清空的,所以何时调用 callback 函数是不确定的
# 参考文献
- http://nodejs.cn/api/process.html
# 对 Node 中的 fs 模块的理解? 有哪些常用方法
# 一、是什么
fs(filesystem),该模块提供本地文件的读写能力,基本上是POSIX文件操作命令的简单包装
可以说,所有与文件的操作都是通过fs核心模块实现
导入模块如下:
const fs = require('fs')
这个模块对所有文件系统操作提供异步(不具有sync 后缀)和同步(具有 sync 后缀)两种操作方式,而供开发者选择
# 二、文件知识
在计算机中有关于文件的知识:
- 权限位 mode
- 标识位 flag
- 文件描述为 fd
权限位 mode
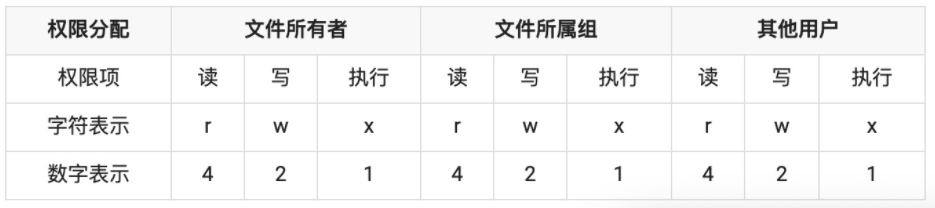
针对文件所有者、文件所属组、其他用户进行权限分配,其中类型又分成读、写和执行,具备权限位 4、2、1,不具备权限为 0
如在linux查看文件权限位:
drwxr-xr-x 1 PandaShen 197121 0 Jun 28 14:41 core
-rw-r--r-- 1 PandaShen 197121 293 Jun 23 17:44 index.md
在开头前十位中,d为文件夹,-为文件,后九位就代表当前用户、用户所属组和其他用户的权限位,按每三位划分,分别代表读(r)、写(w)和执行(x),- 代表没有当前位对应的权限
标识位
标识位代表着对文件的操作方式,如可读、可写、即可读又可写等等,如下表所示:
| 符号 | 含义 |
|---|---|
| r | 读取文件,如果文件不存在则抛出异常。 |
| r+ | 读取并写入文件,如果文件不存在则抛出异常。 |
| rs | 读取并写入文件,指示操作系统绕开本地文件系统缓存。 |
| w | 写入文件,文件不存在会被创建,存在则清空后写入。 |
| wx | 写入文件,排它方式打开。 |
| w+ | 读取并写入文件,文件不存在则创建文件,存在则清空后写入。 |
| wx+ | 和 w+ 类似,排他方式打开。 |
| a | 追加写入,文件不存在则创建文件。 |
| ax | 与 a 类似,排他方式打开。 |
| a+ | 读取并追加写入,不存在则创建。 |
| ax+ | 与 a+ 类似,排他方式打开。 |
文件描述为 fd
操作系统会为每个打开的文件分配一个名为文件描述符的数值标识,文件操作使用这些文件描述符来识别与追踪每个特定的文件
Window系统使用了一个不同但概念类似的机制来追踪资源,为方便用户,NodeJS抽象了不同操作系统间的差异,为所有打开的文件分配了数值的文件描述符
在 NodeJS中,每操作一个文件,文件描述符是递增的,文件描述符一般从 3 开始,因为前面有 0、1、2三个比较特殊的描述符,分别代表 process.stdin(标准输入)、process.stdout(标准输出)和 process.stderr(错误输出)
# 三、方法
下面针对fs模块常用的方法进行展开:
- 文件读取
- 文件写入
- 文件追加写入
- 文件拷贝
- 创建目录
# 文件读取
# fs.readFileSync
同步读取,参数如下:
- 第一个参数为读取文件的路径或文件描述符
- 第二个参数为 options,默认值为 null,其中有 encoding(编码,默认为 null)和 flag(标识位,默认为 r),也可直接传入 encoding
结果为返回文件的内容
const fs = require('fs')
let buf = fs.readFileSync('1.txt')
let data = fs.readFileSync('1.txt', 'utf8')
console.log(buf) // <Buffer 48 65 6c 6c 6f>
console.log(data) // Hello
# fs.readFile
异步读取方法 readFile 与 readFileSync 的前两个参数相同,最后一个参数为回调函数,函数内有两个参数 err(错误)和 data(数据),该方法没有返回值,回调函数在读取文件成功后执行
const fs = require('fs')
fs.readFile('1.txt', 'utf8', (err, data) => {
if (!err) {
console.log(data) // Hello
}
})
# 文件写入
# writeFileSync
同步写入,有三个参数:
第一个参数为写入文件的路径或文件描述符
第二个参数为写入的数据,类型为 String 或 Buffer
第三个参数为 options,默认值为 null,其中有 encoding(编码,默认为 utf8)、 flag(标识位,默认为 w)和 mode(权限位,默认为 0o666),也可直接传入 encoding
const fs = require('fs')
fs.writeFileSync('2.txt', 'Hello world')
let data = fs.readFileSync('2.txt', 'utf8')
console.log(data) // Hello world
# writeFile
异步写入,writeFile 与 writeFileSync 的前三个参数相同,最后一个参数为回调函数,函数内有一个参数 err(错误),回调函数在文件写入数据成功后执行
const fs = require('fs')
fs.writeFile('2.txt', 'Hello world', err => {
if (!err) {
fs.readFile('2.txt', 'utf8', (err, data) => {
console.log(data) // Hello world
})
}
})
# 文件追加写入
# appendFileSync
参数如下:
- 第一个参数为写入文件的路径或文件描述符
- 第二个参数为写入的数据,类型为 String 或 Buffer
- 第三个参数为 options,默认值为 null,其中有 encoding(编码,默认为 utf8)、 flag(标识位,默认为 a)和 mode(权限位,默认为 0o666),也可直接传入 encoding
const fs = require('fs')
fs.appendFileSync('3.txt', ' world')
let data = fs.readFileSync('3.txt', 'utf8')
# appendFile
异步追加写入方法 appendFile 与 appendFileSync 的前三个参数相同,最后一个参数为回调函数,函数内有一个参数 err(错误),回调函数在文件追加写入数据成功后执行
const fs = require('fs')
fs.appendFile('3.txt', ' world', err => {
if (!err) {
fs.readFile('3.txt', 'utf8', (err, data) => {
console.log(data) // Hello world
})
}
})
# 文件拷贝
# copyFileSync
同步拷贝
const fs = require('fs')
fs.copyFileSync('3.txt', '4.txt')
let data = fs.readFileSync('4.txt', 'utf8')
console.log(data) // Hello world
# copyFile
异步拷贝
const fs = require('fs')
fs.copyFile('3.txt', '4.txt', () => {
fs.readFile('4.txt', 'utf8', (err, data) => {
console.log(data) // Hello world
})
})
# 创建目录
# mkdirSync
同步创建,参数为一个目录的路径,没有返回值,在创建目录的过程中,必须保证传入的路径前面的文件目录都存在,否则会抛出异常
// 假设已经有了 a 文件夹和 a 下的 b 文件夹
fs.mkdirSync('a/b/c')
# mkdir
异步创建,第二个参数为回调函数
fs.mkdir('a/b/c', err => {
if (!err) console.log('创建成功')
})
# 参考文献
- http://nodejs.cn/api/fs.html
- https://segmentfault.com/a/1190000019913303
# 对 Node 中的 Buffer 的理解?应用场景?
Buffer 对象是一个类似于数组的对象,它的每个元素都是一个表示 8 位字节的整数。
可以将其看作是一个字节数组,用来存储和操作二进制数据。在前端使用 JS 时不需要操作二进制数据,但在后端有对大文件打开、写入等操作,需要处理二进制数据流。
Buffer 是用于存放二进制数据的缓存区(内存)。比如我们读取大文件时,一次载入内存会占用大量内存,这种情况可以使用 Buffer 将数据一块一块加入到 Bueffer 内存中,然后再以流的形式一段一段传递,这样减少内存占用,加快数据读取处理。
你也可以把 Buffer 理解为你在看在线视频时的缓冲区数据。
现实生活中类似,京东在各地建立的仓储点,这个仓储点就是 Buffer。有了这个仓储点就不需要从商家源头运货了,京东不断的保证仓储点有货,就可以保证最快的把货送到客户手里。
应用场景:
- 网络通信:可以使用 Buffer.from()方法将字符串转换为二进制数据,然后使用 net 模块进行网络通信:
const net = require('net')
const client = net.createConnection({ port: 8080 }, () => {
// 将字符串转换为二进制数据
const data = Buffer.from('Hello, world!', 'utf8')
// 发送数据
client.write(data)
})
2 文件操作,用 Buffer 来存储文件数据:
const fs = require('fs')
// 读取文件,并将数据存储到 Buffer 对象中
const data = fs.readFileSync('/path/to/file')
// 处理数据
// ...
3 加密解密,例如,可以使用 crypto 模块创建加密解密算法需要的二进制数据:
const crypto = require('crypto')
// 创建加密解密算法需要的二进制数据
const key = Buffer.from('mysecretkey', 'utf8')
const iv = Buffer.alloc(16)
// 创建加密解密算法对象
const cipher = crypto.createCipheriv('aes-256-cbc', key, iv)
// 加密数据
const encrypted = Buffer.concat([cipher.update(data), cipher.final()])
4 图像处理:
const fs = require('fs');
const sharp = require('sharp');
// 读取图片文件,并将数据存储到 Buffer 对象中
const data = fs.readFileSync('/path/to/image');
// 处理图片
sharp(data)
.resize(200, 200)
.toFile('/path/to/resized-image', (err, info) => {
// ...
});
# 什么是 I/O?
概念:计算机里所谓的 I/O 指的是输入和输出,但对于前端同学而言,这个定义可能不太好理解。简单点说,需要等待的任务都可以称为 I/O 任务,比如前端的事件处理、网络请求、定时器,后端的文件处理、网络请求、数据库操作,这些都属于 I/O 任务。
异步 I/O:以网络请求任务为例,传统的同步 I/O 指的是一个一个排队执行,一个执行完了再执行下一个,即使线程空闲,也不能执行其他任务。
而异步 I/O 会返回一个标记,告诉调用者 I/O 操作已经开始,但不会阻塞线程。当 I/O 操作完成时,会调用注册的回调函数,将结果返回给调用者。
异步 I/O 使得程序在执行 I/O 操作时不必等待,提高了程序的并发性能。
听起来异步 I/O 很好,那为什么同步 I/O 依然会存在
传统的同步 I/O 操作比异步 I/O 操作更容易理解和编写。异步编程需要开发人员具备较高的技能水平,以及对事件循环、回调函数等概念的深入理解。
对于某些小规模的应用程序或者一些低频次的 I/O 操作,使用异步 I/O 可能不会带来很大的性能提升,而且可能会增加代码的复杂性。
对于一些 CPU 密集型任务,传统 I/O 操作可能比异步 I/O 更快,因为异步 I/O 会在 I/O 操作执行期间增加额外的上下文切换和事件处理负担,从而降低了程序的性能。
CPU 密集和 I/O 密集:
CPU 密集任务指的是纯计算任务。
I/O 密集的任务指的是需要等待的任务。所谓的高并发,显然属于 I/O 密集型任务。
# 对 Node 中的 Stream 的理解?应用场景?
Stream 是一种处理流式数据的抽象接口,用于读取、写入、转换和操作数据流。它是一个基于事件的 API,可以让我们以高效、低延迟的方式处理大型数据集。
说直白点就是基于 Stream 封装的 API,性能更好。
比如读取文件,使用流我们可以一点一点来读取文件,每次只读取或写入文件的一小部分数据块,而不是一次性将整个文件读取或写入到内存中或磁盘中,这样做能够降低内存占用。
- stream 用于处理数据的传输
- 在开发中我们多数使用的是对 stream 的封装,一般不需要自己写 stream 的控制
- stream 主要用在网络请求、文件处理等 IO 操作
- 在处理大文件时才可以体验到 stream 的效率
Stream 流对象是 EventEmitter 的实例,所以拥有事件处理机制。
主要包含以下事件
- open 文件被打开时触发
- close 文件关闭时触发
- data 当有数据读取时触发
- end 数据读取完毕时触发,早于 close 事件
- error 在接收和写入过程中发生错误时触发
可读流
可读流指数据从源头(如磁盘)读取内存,也可以将流理解为 Buffer 的搬运工,将 Buffer 一块块的搬运(流动)到目的地。
- 数据会分块读取
- Buffer 数据是二进制的,所以结果是二进制表示
- 使用这种方式是一块一块读取处理数据,所以要比一次读取文件到内存性能更好
- stream 使用默认的 64KB 的 Buffer
基本操作
下面通过读取超大文件 hd.json ,来体验 Buffer 的操作大数据。
import { createReadStream, createWriteStream } from 'fs'
//创建可读流,将数据以块的形式读取,每次读取一点放在缓存区
const readStream = createReadStream('./hd.txt', {
encoding: 'utf8'
})
const writeStream = createWriteStream('a.txt')
//每次读取到数据时,会触发函数
readStream.on('data', chunk => {
console.log(chunk)
writeStream.write(chunk)
})
可以在读取时设置编码,指定 Buffer 大小
...js
const readStream = createReadStream('./hd.txt', {encoding: 'utf8',highWaterMark: 2 })
...
# 说说 Node 中的 EventEmitter? 如何实现一个 EventEmitter?
EventEmitter 经常在面试的时候会要求手写,因为这玩意用途实在是太广了。比如在 Vue 里面的 EventBus 实现组件通信,其核心就是 EventEmitter。
Node.js 的大多数核心模块都是基于 EventEmitter 实现的,如 http、net、fs,很多第三方库也是基于 EventEmitter 实现的,如 socket.io、nodemailer、cheerio 等。
使用 EventEmitter 的好处是可以用事件的形式来处理异步任务,可以大大简化代码,并且容易处理异常。
举个例子来看看为什么 Nodejs 里大多数模块都要继承 EventEmitter。
这是不使用 EventEmitter 实现的文件读取,所有逻辑都放在一个回调函数里:
const fs = require('fs');
fs.readFile('file.txt', (err, data) => {
if (err) {
console.error(`Failed to read file: ${err}`);
} else {
console.log(`File content: ${data}`);
}
});
这是使用 EventEmitter 的文件读取:
const fs = require('fs');
const stream = fs.createReadStream('file.txt');
stream.on('data', (chunk) => {
console.log(`Received ${chunk.length} bytes of data.`);
});
stream.on('end', () => {
console.log('Finished reading file.');
});
很显然,使用 EventEmitter 之后,处理文件和处理异常的逻辑就被分开了,代码可读性和可维护性都提升了。
# 说说对 Nodejs 中的事件循环机制理解?
# 一、是什么
在浏览器事件循环 (opens new window)中,我们了解到javascript在浏览器中的事件循环机制,其是根据HTML5定义的规范来实现
而在NodeJS中,事件循环是基于libuv实现,libuv是一个多平台的专注于异步 IO 的库,如下图最右侧所示:
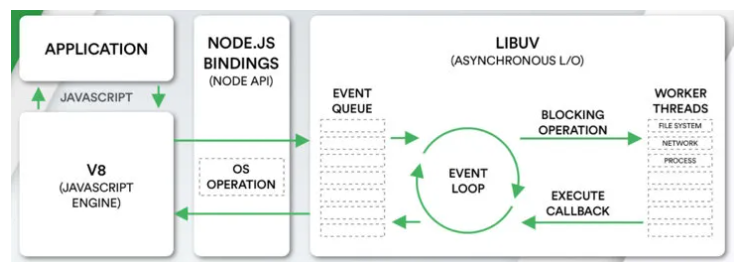
上图EVENT_QUEUE 给人看起来只有一个队列,但EventLoop存在 6 个阶段,每个阶段都有对应的一个先进先出的回调队列
# 二、流程
上节讲到事件循环分成了六个阶段,对应如下:
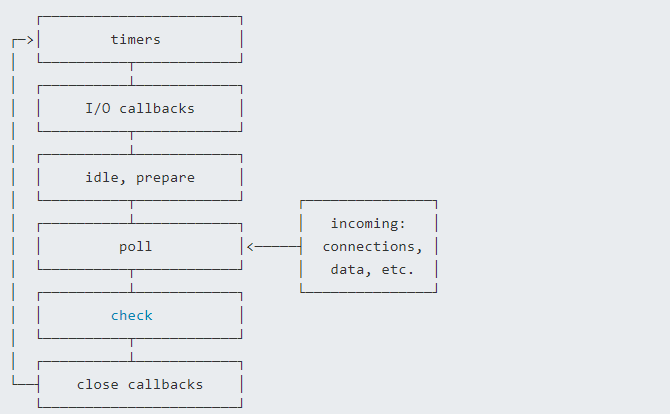
- timers 阶段:这个阶段执行 timer(setTimeout、setInterval)的回调
- 定时器检测阶段(timers):本阶段执行 timer 的回调,即 setTimeout、setInterval 里面的回调函数
- I/O 事件回调阶段(I/O callbacks):执行延迟到下一个循环迭代的 I/O 回调,即上一轮循环中未被执行的一些 I/O 回调
- 闲置阶段(idle, prepare):仅系统内部使用
- 轮询阶段(poll):检索新的 I/O 事件;执行与 I/O 相关的回调(几乎所有情况下,除了关闭的回调函数,那些由计时器和 setImmediate() 调度的之外),其余情况 node 将在适当的时候在此阻塞
- 检查阶段(check):setImmediate() 回调函数在这里执行
- 关闭事件回调阶段(close callback):一些关闭的回调函数,如:socket.on('close', ...)
每个阶段对应一个队列,当事件循环进入某个阶段时, 将会在该阶段内执行回调,直到队列耗尽或者回调的最大数量已执行, 那么将进入下一个处理阶段
除了上述 6 个阶段,还存在process.nextTick,其不属于事件循环的任何一个阶段,它属于该阶段与下阶段之间的过渡, 即本阶段执行结束, 进入下一个阶段前, 所要执行的回调,类似插队
流程图如下所示:

在Node中,同样存在宏任务和微任务,与浏览器中的事件循环相似
微任务对应有:
- next tick queue:process.nextTick
- other queue:Promise 的 then 回调、queueMicrotask
宏任务对应有:
- timer queue:setTimeout、setInterval
- poll queue:IO 事件
- check queue:setImmediate
- close queue:close 事件
其执行顺序为:
- next tick microtask queue
- other microtask queue
- timer queue
- poll queue
- check queue
- close queue
# 三、题目
通过上面的学习,下面开始看看题目
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
console.log('script start')
setTimeout(function() {
console.log('setTimeout0')
}, 0)
setTimeout(function() {
console.log('setTimeout2')
}, 300)
setImmediate(() => console.log('setImmediate'))
process.nextTick(() => console.log('nextTick1'))
async1()
process.nextTick(() => console.log('nextTick2'))
new Promise(function(resolve) {
console.log('promise1')
resolve()
console.log('promise2')
}).then(function() {
console.log('promise3')
})
console.log('script end')
分析过程:
先找到同步任务,输出 script start
遇到第一个 setTimeout,将里面的回调函数放到 timer 队列中
遇到第二个 setTimeout,300ms 后将里面的回调函数放到 timer 队列中
遇到第一个 setImmediate,将里面的回调函数放到 check 队列中
遇到第一个 nextTick,将其里面的回调函数放到本轮同步任务执行完毕后执行
执行 async1 函数,输出 async1 start
执行 async2 函数,输出 async2,async2 后面的输出 async1 end 进入微任务,等待下一轮的事件循环
遇到第二个,将其里面的回调函数放到本轮同步任务执行完毕后执行
遇到 new Promise,执行里面的立即执行函数,输出 promise1、promise2
then 里面的回调函数进入微任务队列
遇到同步任务,输出 script end
执行下一轮回到函数,先依次输出 nextTick 的函数,分别是 nextTick1、nextTick2
然后执行微任务队列,依次输出 async1 end、promise3
执行 timer 队列,依次输出 setTimeout0
接着执行 check 队列,依次输出 setImmediate
300ms 后,timer 队列存在任务,执行输出 setTimeout2
执行结果如下:
script start
async1 start
async2
promise1
promise2
script end
nextTick1
nextTick2
async1 end
promise3
setTimeout0
setImmediate
setTimeout2
最后有一道是关于setTimeout与setImmediate的输出顺序
setTimeout(() => {
console.log('setTimeout')
}, 0)
setImmediate(() => {
console.log('setImmediate')
})
输出情况如下:
情况一:
setTimeout
setImmediate
情况二:
setImmediate
setTimeout
分析下流程:
- 外层同步代码一次性全部执行完,遇到异步 API 就塞到对应的阶段
- 遇到
setTimeout,虽然设置的是 0 毫秒触发,但实际上会被强制改成 1ms,时间到了然后塞入times阶段 - 遇到
setImmediate塞入check阶段 - 同步代码执行完毕,进入 Event Loop
- 先进入
times阶段,检查当前时间过去了 1 毫秒没有,如果过了 1 毫秒,满足setTimeout条件,执行回调,如果没过 1 毫秒,跳过 - 跳过空的阶段,进入 check 阶段,执行
setImmediate回调
这里的关键在于这 1ms,如果同步代码执行时间较长,进入Event Loop的时候 1 毫秒已经过了,setTimeout先执行,如果 1 毫秒还没到,就先执行了setImmediate
# 参考文献
- https://segmentfault.com/a/1190000012258592
- https://juejin.cn/post/6844904100195205133
# 说 Node 文件查找的优先级以及 Require 方法的文件查找策略?
# 说说对中间件概念的理解,如何封装 node 中间件?
Koa 就运用了中间件
Koa 洋葱圈中间件实现原理主要有以下两点:
- 数组里面存函数:使用 middleware 来存储中间函数。
use (fn) {
if (typeof fn !== 'function') throw new TypeError('middleware must be a function!')
debug('use %s', fn._name || fn.name || '-')
this.middleware.push(fn)
return this
}
- compose 函数:将一组中间件函数组合成一个大的异步函数。这个大的异步函数会依次执行每个中间件函数,并将每个中间件函数的执行结果传递给下一个中间件函数。最终,这个大的异步函数会返回一个 Promise 对象,表示整个中间件链的执行结果。
function compose(middleware) {
if (!Array.isArray(middleware)) throw new TypeError('Middleware stack must be an array!')
for (const fn of middleware) {
if (typeof fn !== 'function') throw new TypeError('Middleware must be composed of functions!')
}
return function (context, next) {
let index = -1
return dispatch(0)
function dispatch(i) {
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i
let fn = middleware[i]
if (i === middleware.length) fn = next
if (!fn) return Promise.resolve()
try {
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)))
} catch (err) {
return Promise.reject(err)
}
}
}
}
# 如何实现 jwt 鉴权机制?说说你的思路
# 一、是什么
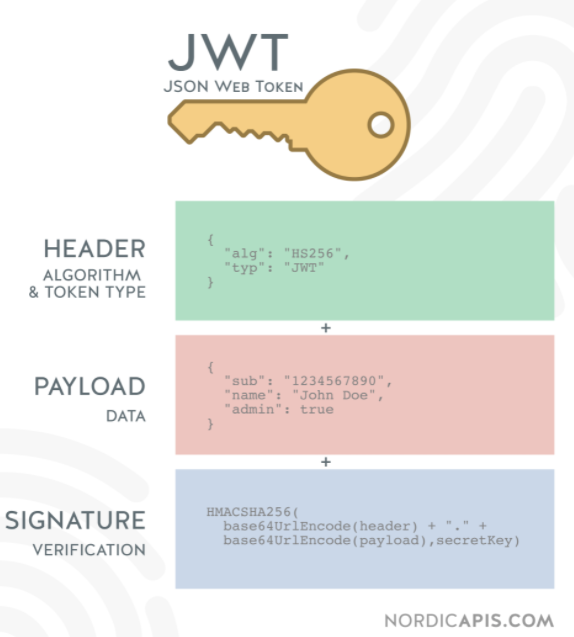
JWT(JSON Web Token),本质就是一个字符串书写规范,如下图,作用是用来在用户和服务器之间传递安全可靠的信息

在目前前后端分离的开发过程中,使用token鉴权机制用于身份验证是最常见的方案,流程如下:
- 服务器当验证用户账号和密码正确的时候,给用户颁发一个令牌,这个令牌作为后续用户访问一些接口的凭证
- 后续访问会根据这个令牌判断用户时候有权限进行访问
Token,分成了三部分,头部(Header)、载荷(Payload)、签名(Signature),并以.进行拼接。其中头部和载荷都是以JSON格式存放数据,只是进行了编码
# header
每个 JWT 都会带有头部信息,这里主要声明使用的算法。声明算法的字段名为alg,同时还有一个typ的字段,默认JWT即可。以下示例中算法为 HS256
{ "alg": "HS256", "typ": "JWT" }
因为 JWT 是字符串,所以我们还需要对以上内容进行 Base64 编码,编码后字符串如下:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9
# payload
载荷即消息体,这里会存放实际的内容,也就是Token的数据声明,例如用户的id和name,默认情况下也会携带令牌的签发时间iat,通过还可以设置过期时间,如下:
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022
}
同样进行 Base64 编码后,字符串如下:
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ
# Signature
签名是对头部和载荷内容进行签名,一般情况,设置一个secretKey,对前两个的结果进行HMACSHA25算法,公式如下:
Signature = HMACSHA256(base64Url(header)+.+base64Url(payload),secretKey)
一旦前面两部分数据被篡改,只要服务器加密用的密钥没有泄露,得到的签名肯定和之前的签名不一致
# 二、如何实现
Token的使用分成了两部分:
- 生成 token:登录成功的时候,颁发 token
- 验证 token:访问某些资源或者接口时,验证 token
# 生成 token
借助第三方库jsonwebtoken,通过jsonwebtoken 的 sign 方法生成一个 token:
第一个参数指的是 Payload
第二个是秘钥,服务端特有
第三个参数是 option,可以定义 token 过期时间
const crypto = require('crypto'),
jwt = require('jsonwebtoken')
// TODO:使用数据库
// 这里应该是用数据库存储,这里只是演示用
let userList = []
class UserController {
// 用户登录
static async login(ctx) {
const data = ctx.request.body
if (!data.name || !data.password) {
return (ctx.body = {
code: '000002',
message: '参数不合法'
})
}
const result = userList.find(
item =>
item.name === data.name &&
item.password ===
crypto
.createHash('md5')
.update(data.password)
.digest('hex')
)
if (result) {
// 生成token
const token = jwt.sign(
{
name: result.name
},
'test_token', // secret
{ expiresIn: 60 * 60 } // 过期时间:60 * 60 s
)
return (ctx.body = {
code: '0',
message: '登录成功',
data: {
token
}
})
} else {
return (ctx.body = {
code: '000002',
message: '用户名或密码错误'
})
}
}
}
module.exports = UserController
在前端接收到token后,一般情况会通过localStorage进行缓存,然后将token放到HTTP请求头Authorization 中,关于Authorization 的设置,前面要加上 Bearer ,注意后面带有空格
axios.interceptors.request.use(config => {
const token = localStorage.getItem('token')
config.headers.common['Authorization'] = 'Bearer ' + token // 留意这里的 Authorization
return config
})
# 校验 token
使用 koa-jwt 中间件进行验证,方式比较简单
/ 注意:放在路由前面
app.use(koajwt({
secret: 'test_token'
}).unless({ // 配置白名单
path: [/\/api\/register/, /\/api\/login/]
}))
- secret 必须和 sign 时候保持一致
- 可以通过 unless 配置接口白名单,也就是哪些 URL 可以不用经过校验,像登陆/注册都可以不用校验
- 校验的中间件需要放在需要校验的路由前面,无法对前面的 URL 进行校验
获取token用户的信息方法如下:
router.get('/api/userInfo',async (ctx,next) =>{
const authorization = ctx.header.authorization // 获取jwt
const token = authorization.replace('Beraer ','')
const result = jwt.verify(token,'test_token')
ctx.body = result
注意:上述的HMA256加密算法为单秘钥的形式,一旦泄露后果非常的危险
在分布式系统中,每个子系统都要获取到秘钥,那么这个子系统根据该秘钥可以发布和验证令牌,但有些服务器只需要验证令牌
这时候可以采用非对称加密,利用私钥发布令牌,公钥验证令牌,加密算法可以选择RS256
# 三、优缺点
优点:
- json 具有通用性,所以可以跨语言
- 组成简单,字节占用小,便于传输
- 服务端无需保存会话信息,很容易进行水平扩展
- 一处生成,多处使用,可以在分布式系统中,解决单点登录问题
- 可防护 CSRF 攻击
缺点:
- payload 部分仅仅是进行简单编码,所以只能用于存储逻辑必需的非敏感信息
- 需要保护好加密密钥,一旦泄露后果不堪设想
- 为避免 token 被劫持,最好使用 https 协议
# 参考文献
- http://www.ruanyifeng.com/blog/2018/07/json_web_token-tutorial.html
- https://blog.wangjunfeng.com/post/golang-jwt/
# 如何实现文件上传?说说你的思路
# 一、是什么
文件上传在日常开发中应用很广泛,我们发微博、发微信朋友圈都会用到了图片上传功能
因为浏览器限制,浏览器不能直接操作文件系统的,需要通过浏览器所暴露出来的统一接口,由用户主动授权发起来访问文件动作,然后读取文件内容进指定内存里,最后执行提交请求操作,将内存里的文件内容数据上传到服务端,服务端解析前端传来的数据信息后存入文件里
对于文件上传,我们需要设置请求头为content-type:multipart/form-data
multipart 互联网上的混合资源,就是资源由多种元素组成,form-data 表示可以使用 HTML Forms 和 POST 方法上传文件
结构如下:
POST /t2/upload.do HTTP/1.1
User-Agent: SOHUWapRebot
Accept-Language: zh-cn,zh;q=0.5
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Content-Length: 60408
Content-Type:multipart/form-data; boundary=ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Host: w.sohu.com
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data; name="city"
Santa colo
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data;name="desc"
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
...
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC
Content-Disposition: form-data;name="pic"; filename="photo.jpg"
Content-Type: application/octet-stream
Content-Transfer-Encoding: binary
... binary data of the jpg ...
--ZnGpDtePMx0KrHh_G0X99Yef9r8JZsRJSXC--
boundary表示分隔符,如果要上传多个表单项,就要使用boundary分割,每个表单项由———XXX开始,以———XXX结尾
而xxx是即时生成的字符串,用以确保整个分隔符不会在文件或表单项的内容中出现
每个表单项必须包含一个 Content-Disposition 头,其他的头信息则为可选项, 比如 Content-Type
Content-Disposition 包含了 type和 一个名字为name的 parameter,type 是 form-data,name参数的值则为表单控件(也即 field)的名字,如果是文件,那么还有一个 filename参数,值就是文件名
Content-Disposition: form-data; name="user"; filename="logo.png"
至于使用multipart/form-data,是因为文件是以二进制的形式存在,其作用是专门用于传输大型二进制数据,效率高
# 二、如何实现
关于文件的上传的上传,我们可以分成两步骤:
- 文件的上传
- 文件的解析
# 文件上传
传统前端文件上传的表单结构如下:
<form action="http://localhost:8080/api/upload" method="post" enctype="multipart/form-data">
<input type="file" name="file" id="file" value="" multiple="multiple" />
<input type="submit" value="提交" />
</form>
action 就是我们的提交到的接口,enctype="multipart/form-data" 就是指定上传文件格式,input 的 name 属性一定要等于file
# 文件解析
在服务器中,这里采用koa2中间件的形式解析上传的文件数据,分别有下面两种形式:
- koa-body
- koa-multer
# koa-body
安装依赖
npm install koa-body
引入koa-body中间件
const koaBody = require('koa-body')
app.use(
koaBody({
multipart: true,
formidable: {
maxFileSize: 200 * 1024 * 1024 // 设置上传文件大小最大限制,默认2M
}
})
)
获取上传的文件
const file = ctx.request.files.file // 获取上传文件
获取文件数据后,可以通过fs模块将文件保存到指定目录
router.post('/uploadfile', async (ctx, next) => {
// 上传单个文件
const file = ctx.request.files.file // 获取上传文件
// 创建可读流
const reader = fs.createReadStream(file.path)
let filePath = path.join(__dirname, 'public/upload/') + `/${file.name}`
// 创建可写流
const upStream = fs.createWriteStream(filePath)
// 可读流通过管道写入可写流
reader.pipe(upStream)
return (ctx.body = '上传成功!')
})
# koa-multer
安装依赖:
npm install koa-multer
使用 multer 中间件实现文件上传
const storage = multer.diskStorage({
destination: (req, file, cb) => {
cb(null, './upload/')
},
filename: (req, file, cb) => {
cb(null, Date.now() + path.extname(file.originalname))
}
})
const upload = multer({
storage
})
const fileRouter = new Router()
fileRouter.post('/upload', upload.single('file'), (ctx, next) => {
console.log(ctx.req.file) // 获取文件
})
app.use(fileRouter.routes())
# 参考文献
- https://segmentfault.com/a/1190000037411957
- https://www.jianshu.com/p/29e38bcc8a1d
# 如果让你来设计一个分页功能, 你会怎么设计? 前后端如何交互?
# 一、是什么
在我们做数据查询的时候,如果数据量很大,比如几万条数据,放在一个页面显示的话显然不友好,这时候就需要采用分页显示的形式,如每次只显示 10 条数据

要实现分页功能,实际上就是从结果集中显示第 1~10 条记录作为第 1 页,显示第 11~20 条记录作为第 2 页,以此类推
因此,分页实际上就是从结果集中截取出第 M~N 条记录
# 二、如何实现
前端实现分页功能,需要后端返回必要的数据,如总的页数,总的数据量,当前页,当前的数据
{
"totalCount": 1836, // 总的条数
"totalPages": 92, // 总页数
"currentPage": 1 // 当前页数
"data": [ // 当前页的数据
{
...
}
]
后端采用mysql作为数据的持久性存储
前端向后端发送目标的页码page以及每页显示数据的数量pageSize,默认情况每次取 10 条数据,则每一条数据的起始位置start为:
const start = (page - 1) * pageSize
当确定了limit和start的值后,就能够确定SQL语句:
const sql = `SELECT * FROM record limit ${pageSize} OFFSET ${start};`
上诉SQL语句表达的意思为:截取从start到start+pageSize之间(左闭右开)的数据
关于查询数据总数的SQL语句为,record为表名:
SELECT COUNT(*) FROM record
因此后端的处理逻辑为:
- 获取用户参数页码数 page 和每页显示的数目 pageSize ,其中 page 是必须传递的参数,pageSize 为可选参数,默认为 10
- 编写 SQL 语句,利用 limit 和 OFFSET 关键字进行分页查询
- 查询数据库,返回总数据量、总页数、当前页、当前页数据给前端
代码如下所示:
router.all('/api', function(req, res, next) {
var param = ''
// 获取参数
if (req.method == 'POST') {
param = req.body
} else {
param = req.query || req.params
}
if (param.page == '' || param.page == null || param.page == undefined) {
res.end(JSON.stringify({ msg: '请传入参数page', status: '102' }))
return
}
const pageSize = param.pageSize || 10
const start = (param.page - 1) * pageSize
const sql = `SELECT * FROM record limit ${pageSize} OFFSET ${start};`
pool.getConnection(function(err, connection) {
if (err) throw err
connection.query(sql, function(err, results) {
connection.release()
if (err) {
throw err
} else {
// 计算总页数
var allCount = results[0][0]['COUNT(*)']
var allPage = parseInt(allCount) / 20
var pageStr = allPage.toString()
// 不能被整除
if (pageStr.indexOf('.') > 0) {
allPage = parseInt(pageStr.split('.')[0]) + 1
}
var list = results[1]
res.end(
JSON.stringify({
msg: '操作成功',
status: '200',
totalPages: allPage,
currentPage: param.page,
totalCount: allCount,
data: list
})
)
}
})
})
})
# 三、总结
通过上面的分析,可以看到分页查询的关键在于,要首先确定每页显示的数量pageSize,然后根据当前页的索引pageIndex(从 1 开始),确定LIMIT和OFFSET应该设定的值:
- LIMIT 总是设定为 pageSize
- OFFSET 计算公式为 pageSize * (pageIndex - 1)
确定了这两个值,就能查询出第 N页的数据
# 参考文献
- https://www.liaoxuefeng.com/wiki/1177760294764384/1217864791925600
# Node 性能如何进行监控以及优化?
# 一、 是什么
Node作为一门服务端语言,性能方面尤为重要,其衡量指标一般有如下:
- CPU
- 内存
- I/O
- 网络
# CPU
主要分成了两部分:
- CPU 负载:在某个时间段内,占用以及等待 CPU 的进程总数
- CPU 使用率:CPU 时间占用状况,等于 1 - 空闲 CPU 时间(idle time) / CPU 总时间
这两个指标都是用来评估系统当前 CPU 的繁忙程度的量化指标
Node应用一般不会消耗很多的CPU,如果CPU占用率高,则表明应用存在很多同步操作,导致异步任务回调被阻塞
# 内存指标
内存是一个非常容易量化的指标。 内存占用率是评判一个系统的内存瓶颈的常见指标。 对于 Node 来说,内部内存堆栈的使用状态也是一个可以量化的指标
// /app/lib/memory.js
const os = require('os')
// 获取当前Node内存堆栈情况
const { rss, heapUsed, heapTotal } = process.memoryUsage()
// 获取系统空闲内存
const sysFree = os.freemem()
// 获取系统总内存
const sysTotal = os.totalmem()
module.exports = {
memory: () => {
return {
sys: 1 - sysFree / sysTotal, // 系统内存占用率
heap: heapUsed / headTotal, // Node堆内存占用率
node: rss / sysTotal // Node占用系统内存的比例
}
}
}
- rss:表示 node 进程占用的内存总量。
- heapTotal:表示堆内存的总量。
- heapUsed:实际堆内存的使用量。
- external :外部程序的内存使用量,包含 Node 核心的 C++程序的内存使用量
在Node中,一个进程的最大内存容量为 1.5GB。因此我们需要减少内存泄露
# 磁盘 I/O
硬盘的IO 开销是非常昂贵的,硬盘 IO 花费的 CPU 时钟周期是内存的 164000 倍
内存 IO比磁盘IO 快非常多,所以使用内存缓存数据是有效的优化方法。常用的工具如 redis、memcached等
并不是所有数据都需要缓存,访问频率高,生成代价比较高的才考虑是否缓存,也就是说影响你性能瓶颈的考虑去缓存,并且而且缓存还有缓存雪崩、缓存穿透等问题要解决
# 二、如何监控
关于性能方面的监控,一般情况都需要借助工具来实现
这里采用Easy-Monitor 2.0,其是轻量级的 Node.js 项目内核性能监控 + 分析工具,在默认模式下,只需要在项目入口文件 require 一次,无需改动任何业务代码即可开启内核级别的性能监控分析
使用方法如下:
在你的项目入口文件中按照如下方式引入,当然请传入你的项目名称:
const easyMonitor = require('easy-monitor')
easyMonitor('你的项目名称')
打开你的浏览器,访问 http://localhost:12333 ,即可看到进程界面
关于定制化开发、通用配置项以及如何动态更新配置项详见官方文档
# 三、如何优化
关于Node的性能优化的方式有:
- 使用最新版本 Node.js
- 正确使用流 Stream
- 代码层面优化
- 内存管理优化
# 使用最新版本 Node.js
每个版本的性能提升主要来自于两个方面:
- V8 的版本更新
- Node.js 内部代码的更新优化
# 正确使用流 Stream
在Node中,很多对象都实现了流,对于一个大文件可以通过流的形式发送,不需要将其完全读入内存
const http = require('http')
const fs = require('fs')
// bad
http.createServer(function(req, res) {
fs.readFile(__dirname + '/data.txt', function(err, data) {
res.end(data)
})
})
// good
http.createServer(function(req, res) {
const stream = fs.createReadStream(__dirname + '/data.txt')
stream.pipe(res)
})
# 代码层面优化
合并查询,将多次查询合并一次,减少数据库的查询次数
// bad
for user_id in userIds
let account = user_account.findOne(user_id)
// good
const user_account_map = {} // 注意这个对象将会消耗大量内存。
user_account.find(user_id in user_ids).forEach(account){
user_account_map[account.user_id] = account
}
for user_id in userIds
var account = user_account_map[user_id]
# 内存管理优化
在 V8 中,主要将内存分为新生代和老生代两代:
- 新生代:对象的存活时间较短。新生对象或只经过一次垃圾回收的对象
- 老生代:对象存活时间较长。经历过一次或多次垃圾回收的对象
若新生代内存空间不够,直接分配到老生代
通过减少内存占用,可以提高服务器的性能。如果有内存泄露,也会导致大量的对象存储到老生代中,服务器性能会大大降低
如下面情况:
const buffer = fs.readFileSync(__dirname + '/source/index.htm')
app.use(
mount('/', async ctx => {
ctx.status = 200
ctx.type = 'html'
ctx.body = buffer
leak.push(fs.readFileSync(__dirname + '/source/index.htm'))
})
)
const leak = []
leak的内存非常大,造成内存泄露,应当避免这样的操作,通过减少内存使用,是提高服务性能的手段之一
而节省内存最好的方式是使用池,其将频用、可复用对象存储起来,减少创建和销毁操作
例如有个图片请求接口,每次请求,都需要用到类。若每次都需要重新 new 这些类,并不是很合适,在大量请求时,频繁创建和销毁这些类,造成内存抖动
使用对象池的机制,对这种频繁需要创建和销毁的对象保存在一个对象池中。每次用到该对象时,就取对象池空闲的对象,并对它进行初始化操作,从而提高框架的性能
# 参考文献
- https://segmentfault.com/a/1190000039327565
- https://zhuanlan.zhihu.com/p/50055740
- https://segmentfault.com/a/1190000010231628
# package.json 中 scripts 的 postinstall, install, preinstall
在前端开发中,package.json 文件是一个非常核心的组成部分,特别是在使用 Node.js 和 npm 管理项目依赖时。package.json 中的 scripts 字段允许开发者定义在特定时机自动运行的脚本。这些脚本在项目的生命周期中的特定阶段被执行,例如安装、测试、启动等。
对于 postinstall、install 和 preinstall 这三个脚本,它们主要关联于依赖项的安装过程。下面是每个脚本的详细说明:
# preinstall
- 触发时机:在 npm 开始安装当前项目的依赖之前执行。
- 用途:通常用于执行一些必要的准备工作,比如设置环境变量,检查系统环境是否符合特定要求等。
# install
- 触发时机:在
npm install命令执行时,这个脚本被触发。 - 用途:
install脚本通常是用来编译或构建项目。它可以被用作自动触发编译过程,例如对 TypeScript 项目进行编译或执行其他构建任务。不过,在实践中,install通常不需要显式定义,因为 npm 默认行为已经涵盖了安装依赖的操作。
# postinstall
- 触发时机:在 npm 安装项目依赖后执行。
- 用途:这是最常用的脚本之一,用于在依赖安装完成后执行一些后处理操作,例如执行数据库迁移、本地化的构建脚本或者其他需要在依赖完全安装后执行的任务。
这些脚本在自动化和简化开发流程中扮演了重要的角色,可以显著提高开发效率和项目的可维护性。它们是自动化部署流程的重要组成部分,特别是在持续集成/持续部署 (CI/CD) 环境中。
参考
- https://www.ruanyifeng.com/blog/2016/10/npm_scripts.html
# PM2
M2 是一个守护进程管理器,它将帮助您管理和保持应用程序在线。PM2 的入门非常简单,它以简单直观的 CLI 形式提供,可通过 NPM 进行安装。
pm2 官网 https://pm2.keymetrics.io/
https://docs.ffffee.com/nodejs/pm2-quickstart.html
pnpm add -g pm2@latest
# or
yarn global add pm2
# or
npm install pm2@latest -g
常用命令
# 执行命令创建配置文件
pm2 init simple
# 执行以下命令运行
pm2 start app.ts
# 停止项目
pm2 stop app.ts
# 文件更改时监视并重新启动应用程序
pm2 start app.ts --watch
# 显示进程状态
pm2 list
# 查看 log
pm2 log
# 删除 id 为 0 的进程
pm2 delete 0
# 从 pm2 列表中删除所有流程
pm2 delete all
# 查看资源占用
pm2 monit
# 对 Node 中 CommonJS 和 ES Modules,及 Node 发展的理解
# 一、Node.js 中 require 和 .mjs 的使用
Node.js 提供了两种模块系统:CommonJS(使用 require)和 ES 模块(使用 import/export,通常与 .mjs 文件关联)。这两种系统在 Node.js 中并存,但适用场景和配置方式不同。
# 1. CommonJS(require 和 module.exports)
概述:
- CommonJS 是 Node.js 传统的模块系统,默认使用
.js文件。 - 使用
require引入模块,module.exports或exports导出模块。 - 同步加载模块,适合服务器端开发。
- CommonJS 是 Node.js 传统的模块系统,默认使用
使用场景:
- 传统 Node.js 项目(如 Express 应用)。
- 需要兼容旧代码或依赖 CommonJS 格式的第三方库(如
fs、http)。
代码示例:
// math.js module.exports = { add: (a, b) => a + b } // index.js const math = require('./math') console.log(math.add(2, 3)) // 输出: 5示例结合正则表达式验证邮箱:
// validate.js const regex = /^(\S+)@([a-z0-9A-Z]+(-[a-z0-9A-Z]+)?\.)+[a-zA-Z]{2,}$/ module.exports = { validateEmail: email => regex.test(email) } // index.js const validate = require('./validate') console.log(validate.validateEmail('user@domain.com')) // true console.log(validate.validateEmail('invalid@domain.commfdhaosdfjasda')) // false
注意事项:
require是同步的,适合加载本地模块,但不适合浏览器环境。- 默认情况下,Node.js 将
.js文件视为 CommonJS,除非配置了type: "module"。 - 不能直接在 CommonJS 中使用
import/export,否则会抛出语法错误。
# 2. ES 模块(.mjs 和 import/export)
概述:
- ES 模块是 ECMAScript 标准化的模块系统,Node.js 从 12.x 开始实验性支持,14.x 后稳定。
- 使用
import引入模块,export导出模块。 - 默认异步加载,支持动态导入,适合现代 JavaScript 项目。
- 使用
.mjs文件扩展名明确表示 ES 模块,或者在package.json中设置"type": "module"。
使用场景:
- 现代 Node.js 项目,特别是在需要与前端代码(React、Vue 等)保持一致时。
- 使用支持 ES 模块的库(如
node-fetch3.x)。 - 需要动态导入或 tree-shaking 优化。
代码示例:
// math.mjs export const add = (a, b) => a + b // index.mjs import { add } from './math.mjs' console.log(add(2, 3)) // 输出: 5示例结合正则表达式验证邮箱:
// validate.mjs const regex = /^(\S+)@([a-z0-9A-Z]+(-[a-z0-9A-Z]+)?\.)+[a-zA-Z]{2,}$/ export const validateEmail = email => regex.test(email) // index.mjs import { validateEmail } from './validate.mjs' console.log(validateEmail('user@domain.com')) // true console.log(validateEmail('invalid@domain.commfdhaosdfjasda')) // false
配置 ES 模块:
使用
.mjs文件:Node.js 自动将.mjs文件视为 ES 模块,无需额外配置。node index.mjs使用
.js文件:在package.json中添加"type": "module",使所有.js文件默认使用 ES 模块:{ "type": "module" }示例:
// validate.js const regex = /^(\S+)@([a-z0-9A-Z]+(-[a-z0-9A-Z]+)?\.)+[a-zA-Z]{2,}$/ export const validateEmail = email => regex.test(email) // index.js import { validateEmail } from './validate.js' console.log(validateEmail('user@domain.com')) // true如果
package.json中没有"type": "module",.js文件默认使用 CommonJS。
动态导入:
- ES 模块支持动态导入,适合按需加载模块:
// index.mjs const { validateEmail } = await import('./validate.mjs') console.log(validateEmail('user@domain.com')) // true
- ES 模块支持动态导入,适合按需加载模块:
注意事项:
.mjs文件不能使用require或module.exports,否则会抛出错误。- 部分第三方库仍只支持 CommonJS,可能需要额外配置(如使用
createRequire)。 - 异步导入可能增加复杂性,但更灵活。
# 3. CommonJS 和 ES 模块的互操作
从 ES 模块导入 CommonJS:
ES 模块可以直接导入 CommonJS 模块:
// commonjs-module.js module.exports = { foo: 'bar' } // index.mjs import commonjsModule from './commonjs-module.js' console.log(commonjsModule.foo) // bar
从 CommonJS 导入 ES 模块:
CommonJS 不能直接使用
import,但可以使用动态导入或createRequire:// es-module.mjs export const foo = 'bar' // index.js (CommonJS) const { createRequire } = require('module') const require = createRequire(import.meta.url) const esModule = require('./es-module.mjs') console.log(esModule.foo) // bar或者使用动态导入:
// index.js ;(async () => { const { foo } = await import('./es-module.mjs') console.log(foo) // bar })()
注意:互操作可能导致兼容性问题,建议尽量统一模块系统(例如全用 ES 模块)。
# 4. 如何选择 require 和 .mjs
- 使用 CommonJS(
require):- 项目依赖大量 CommonJS 库(如老版本的
express)。 - 团队熟悉 CommonJS,迁移成本高。
- 简单项目,不需要 ES 模块的动态导入或 tree-shaking。
- 项目依赖大量 CommonJS 库(如老版本的
- 使用 ES 模块(
.mjs或"type": "module"):- 新项目,追求现代 JavaScript 标准。
- 与前端代码共享模块(如使用 Vite 或 Rollup 打包)。
- 需要动态导入或支持新顶级域名(如结合正则表达式验证复杂邮箱)。
- 混合使用:
- 在过渡期,使用
createRequire或动态导入处理兼容性问题。 - 逐步将 CommonJS 模块重写为 ES 模块。
- 在过渡期,使用
# 二、Node.js 当前发展现状(截至 2025 年 4 月 28 日)
Node.js 作为服务器端 JavaScript 运行时,近年来持续快速发展,社区活跃,生态系统庞大。以下是从功能更新、社区动态和行业采用等方面对 Node.js 发展的总结,部分信息基于 X 平台和网络搜索的最新动态。
# 1. 版本和功能更新
- 最新版本:
- 截至 2025 年 4 月,Node.js 的最新 LTS(长期支持)版本为 20.x(2023 年 10 月发布,维护至 2026 年 4 月),最新当前版本为 22.x(2024 年 10 月发布)。
- Node.js 保持每半年发布一个新版本(偶数版本,如 22、24),奇数版本为实验性版本。
- 关键功能更新:
- ES 模块支持:ES 模块已完全稳定,Node.js 22.x 进一步优化了模块加载性能,支持
.mjs和"type": "module"成为主流。 - V8 引擎升级:Node.js 22.x 使用 V8 12.x,支持最新的 JavaScript 特性(如
Array.fromAsync、WebAssembly 增强),对正则表达式性能有优化。 - 内置测试框架:Node.js 18.x 引入了内置测试模块(
node:test),22.x 增强了测试覆盖率报告,减少对 Mocha/Jest 的依赖。 - HTTP/2 和 Web 标准:Node.js 强化了对 HTTP/2 和 Web API(如
fetch、Web Streams)的支持,与浏览器环境更接近。 - 性能优化:22.x 改进了事件循环和垃圾回收,适合高并发应用(如实时聊天、API 服务器)。
- 单文件可执行文件:Node.js 20.x 引入了实验性的单文件打包功能,22.x 进一步完善,方便部署。
- ES 模块支持:ES 模块已完全稳定,Node.js 22.x 进一步优化了模块加载性能,支持
# 2. 社区和生态
- 活跃社区:
- Node.js 在 GitHub(https://github.com/nodejs/node)有超过 100k 星标,社区贡献者众多。
- X 平台上,@nodejs 账号定期发布更新,开发者讨论聚焦性能优化、ES 模块迁移和微服务架构。
- 2024 年 Node.js Conf(线上/线下)吸引了大量开发者,讨论了 AI 驱动开发和 Node.js 在边缘计算的应用。
- 生态系统:
- 框架:Express 仍是最流行的 Web 框架,但 Fastify 和 NestJS 因性能和 TypeScript 支持快速增长。
- 工具:Vite、esbuild 等现代构建工具与 Node.js 集成紧密,支持 ES 模块。
- 库:大多数新库(如
node-fetch3.x)默认支持 ES 模块,推动了模块系统现代化。
- 文档改进:
- 官方文档(https://nodejs.org/en/docs/)持续优化,新增了更多 ES 模块示例。
- 社区项目(如上文提到的 GPT-4 重写文档)提供了更简洁的替代文档。
# 3. 行业采用
- 广泛应用:
- Node.js 被广泛用于 Web 开发(Netflix、LinkedIn)、微服务(Uber)、实时应用(Discord)、CLI 工具(Vite、ESLint)等。
- X 平台上,开发者提到 Node.js 在边缘计算(如 Cloudflare Workers)和 AI 后端(与 TensorFlow.js 集成)中的使用增加。
- 挑战:
- CommonJS 到 ES 模块的迁移仍是痛点,许多旧项目依赖 CommonJS,导致兼容性问题。
- 性能瓶颈在极高并发场景下仍需优化,部分开发者转向 Bun 或 Deno(但 Node.js 生态更成熟)。
- 竞争与替代:
- Deno:强调安全性和内置 TypeScript 支持,但生态远不如 Node.js。
- Bun:以性能为卖点,2024 年达到 1.0,但在生产环境稳定性仍需验证。
- Node.js 凭借成熟生态和广泛采用,短期内仍是服务器端 JavaScript 的首选。
# 三、总结与建议
# require 和 .mjs 使用建议
- 新项目:优先使用 ES 模块(
.mjs或"type": "module"),因为它符合现代 JavaScript 标准,易于与前端生态集成。 - 旧项目:继续使用 CommonJS,但考虑逐步迁移到 ES 模块,使用
createRequire或动态导入过渡。 - 正则表达式场景:无论是 CommonJS 还是 ES 模块,都可以将正则表达式逻辑封装为独立模块(如上文示例),提高复用性。
- 最佳实践:
- 始终在
package.json中明确"type",避免模块类型混淆。 - 使用工具(如
esbuild)检查模块兼容性。 - 测试模块加载性能,特别是在动态导入大量正则表达式逻辑时。
- 始终在
# 讲一下常见的 Nodejs 框架?
- Koa:一个轻量的 Nodejs 框架,代码非常简洁。采用洋葱圈模型中间件,非常方便扩展功能,但是开发后端 API 需要进行再封装。
- Express:Express 也是一个轻量框架,Express 和 Koa 的区别在于中间件机制。但总体差别不是很大,绝大多数 Nodejs 框架都是在 Koa 或者 Express 基础上封装的。
- Eggjs:基于 Koa 封装的框架,整合了数据库、路由、安全防护、日志记录、异常处理等中间件,可以用来快速开发 Rest 或者 Restful API 项目。 -Nestjs:基于 TS,使用了大量的装饰器语法,开发体验类似于 Java 的 Springboot。除此之外,Nestjs 还提供了 GraphQL、WebSocket、各种 MQ 和微服务的解决方案,比较适合大型后端项目的开发。
# 什么是 BFF?
BFF(Backend For Frontend),说白了就是中间层,由前端同学开发的后端项目。
最常见的 BFF 项目像 SSR 和 GraphQL。SSR 用来解决 SEO 问题,GraphQL 用来聚合数据,解决 API 查询的问题。
# 什么是 ORM?Nodejs 的 ORM 框架有哪些?
ORM 框架是通过对 SQL 语句进行封装,并将数据库的数据表和用户代码里的模型对象进行自动映射。
这样开发者使用时只需要调用模型对象的方法就能实现对数据库的增删改查,不用手写太多的 SQL 了。
Node.js 中比较流行的 ORM 框架有:
- Sequelize:基于 JS,在 Koa、Express、Egg 这样的框架里操作数据库用 Sequelize 比较多,当然 Sequelize 经过一定扩展也可以支持 TS。
- TypeORM:基于 TS,Nest 框架首选 TypeORM。
# 有没有了解过 Redis?
可以从以下方面来回答:
- 用 Redis 实现缓存:将热门数据和热门页面存到 Redis 进行缓存,比如热门商品信息,商品页面和网站首页。
- 缓存遇到的问题:缓存穿透、缓存雪崩、缓存击穿。
- Redis 的进阶功能:Redis 有各种数据结构,除了缓存之外,还能实现很多功能。比如:消息队列、附近的人、排行榜等等。
- Redis 持久化:Redis 可以将缓存持久化到本地,持久化策略包括 RDB 和 AOF。
- 集群:如果单机 Redis 不够用的话,可以考虑搭建 Redis 集群,Redis 集群有主从和哨兵两种模式。
Redis 对于后端来说,是一个专门的话题
# 有没有做过数据库优化?
常见的优化有:
- 使用 explain 执行计划查看 SQL 的执行信息,进而定位慢 SQL 来源。
- 索引是 Mysql 调优首先能想到的方案,合理设置索引可以很大程度上提高查询效率。
- 大分页也是一个常见的性能问题出现的地方,因为 MySQL 需要扫描大量的数据,造成性能瓶颈。可以通过使用主键或者游标分页的方式来优化。
- 读写分离,单机顶不住的时候,可以使用主从架构,把数据库读写分担到不同的机器上。
- 分库分表,如果数据表存了海量数据,除了读写分离之外,还要考虑分库分表,把一张表分成多张表,减轻数据库压力。
数据库优化也是一个很大的话题,此处仅作简要总结
# 有了解过分布式和微服务吗?
当单体应用撑不住的时候,就得考虑上集群,把应用部署在多个机器上,就形成了分布式架构。
分布式的集群不仅带来了算力和并发能力,也带来了各种问题,这其中包括:分布式通信、分布式事务、分布式 id、分布式容错、负载均衡等。
所以就需要有各种中间件来解决这些问题,比如 Nginx、Zookeeper、Dubbo、MQ、RPC 等。
然后当项目规模进一步扩大的时候,不仅要考虑集群,还要考虑项目的拆分,这时候就要上微服务架构了。把一个大项目根据业务拆分成很多功能单一的模块,可以由不同的团队独立开发和部署。
比如一个电商的后台 API,可以拆分成用户服务、商品服务、订单服务、优惠券服务、广告服务,这些服务由不同的团队去维护。
当然,微服务也带来了更多的复杂性,所以就会有像 Spring Cloud、Spring Cloud Alibaba 这样的解决方案去解决这些复杂性。
# 参考
- https://vue3js.cn/interview/NodeJS/